Inside React Query
tkdodo의 블로그 글 Inside React Query를 번역한 글입니다.
최근 React Query가 내부적으로 어떻게 동작하는지 질문을 많이 받았다. 언제 re-render해야하는지 어떻게 아는 건가요? 어떻게 중복을 제거하는 건가요? 어떻게 프레임워크에 구애받지 않는 건가요?
좋은 질문들이다. 우리가 사랑하는 비동기 상태 관리 라이브러리의 내부에 대해 알아보고 useQuery를 실행할 때 어떤 일이 실제로 일어나는지 분석해보자.
QueryClient
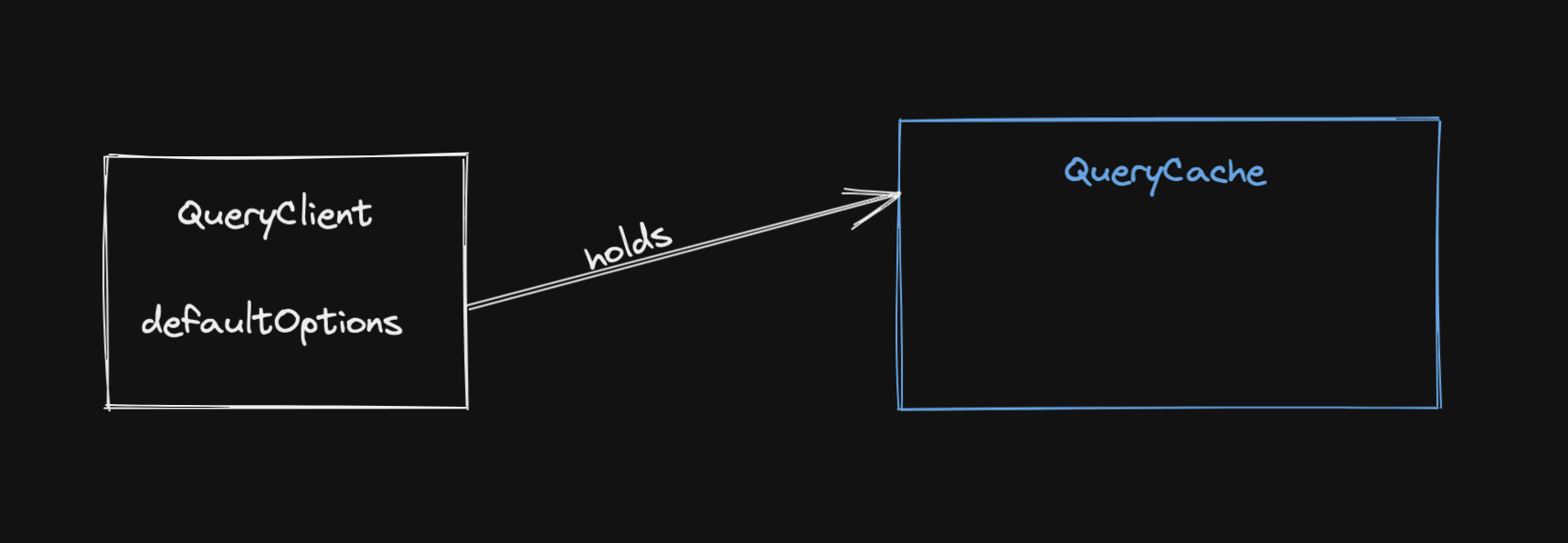
모든 것은 QueryClient로부터 시작한다. 어플리케이션을 시작할때 만들고 QueryClientProvider를 통해 어디서나 사용 가능하다.
import { QueryClient, QueryClientProvider } from "@tanstack/react-query";
// ⬇️ this creates the client
const queryClient = new QueryClient();
function App() {
return (
// ⬇️ this distributes the client
<QueryClientProvider client={queryClient}>
<RestOfYourApp />
</QueryClientProvider>
);
}
QueryClientProvider는 React Context를 사용하여 QueryClient를 전체 어플리케이션에 분배한다. client 자체는 안정적인 값이다. 한 번만 생성됨으로(무심코 너무 자주 재성성되지 않도록 조심하자) Context를 사용하기 완벽한 곳이다.
QueryClientProvider는 앱을 re-render하지 않고, useQueryClient를 통해 client에 접근할 수 있도록 해준다.
캐시를 담는 그릇
잘 알려지지 않았을 수 있지만, QueryClient 자체는 많은 일을 하지 않는다. New QueryClient를 만들면 자동으로 생성되는 QueryCache와 MutationCache의 컨테이너이다.
또한 모든 query 및 mutation에 대해 설정할 수 있는 몇 가지 기본값을 가지고 있으며 캐시 작업을 위한 편리한 method를 제공한다. 우리는 대부분의 경우 캐시와 직접 상호작용하지 않고 QueryClient를 통해 캐시에 접근한다.
QueryCache
좋다, client가 캐시를 사용할 수 있게 해주었다. 그럼 캐시가 무엇인가?
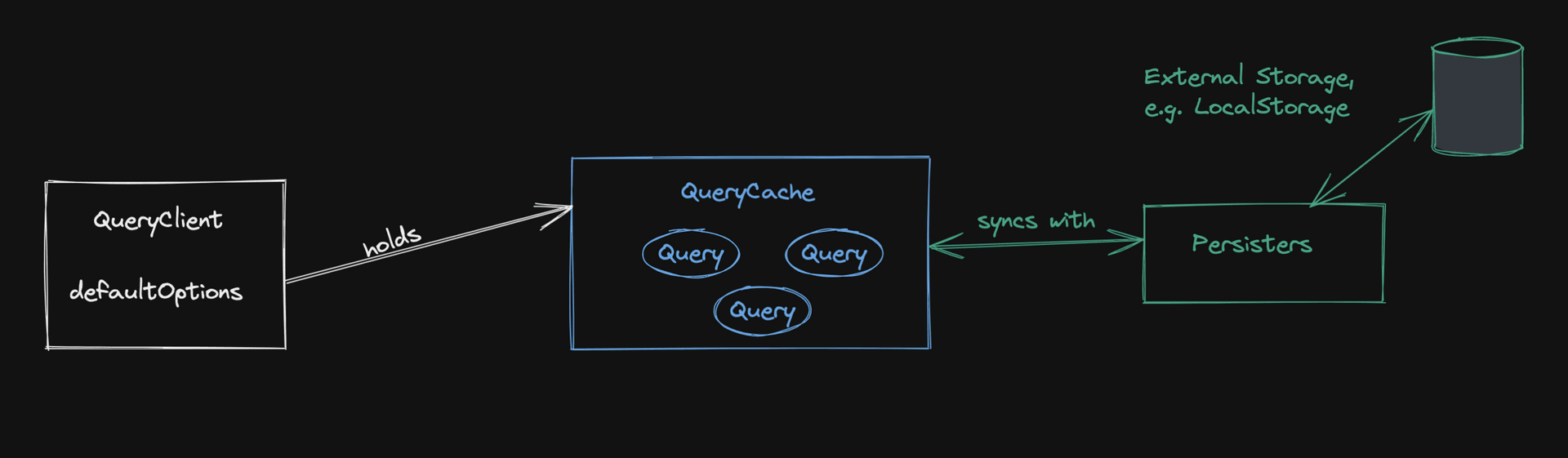
간단히 말해서 QueryCache는 키가 안정적이게 직렬화된 queryKeys의 버전(queryKeyHash라고 한다)이고, 값이 Query 클래스의 인스턴스인 in-memory object이다.
React Query는 기본적으로 in-memory에만 데이터를 저장하고 다른 곳에는 저장하지 않는다는 것을 이해하는 것이 중요하다고 생각한다. 브라우저 페이지를 새로고침하면 캐시는 사라진다. localstorage와 같은 외부 저장소에 캐시를 쓰려면 persisters 를 봐라.
Query
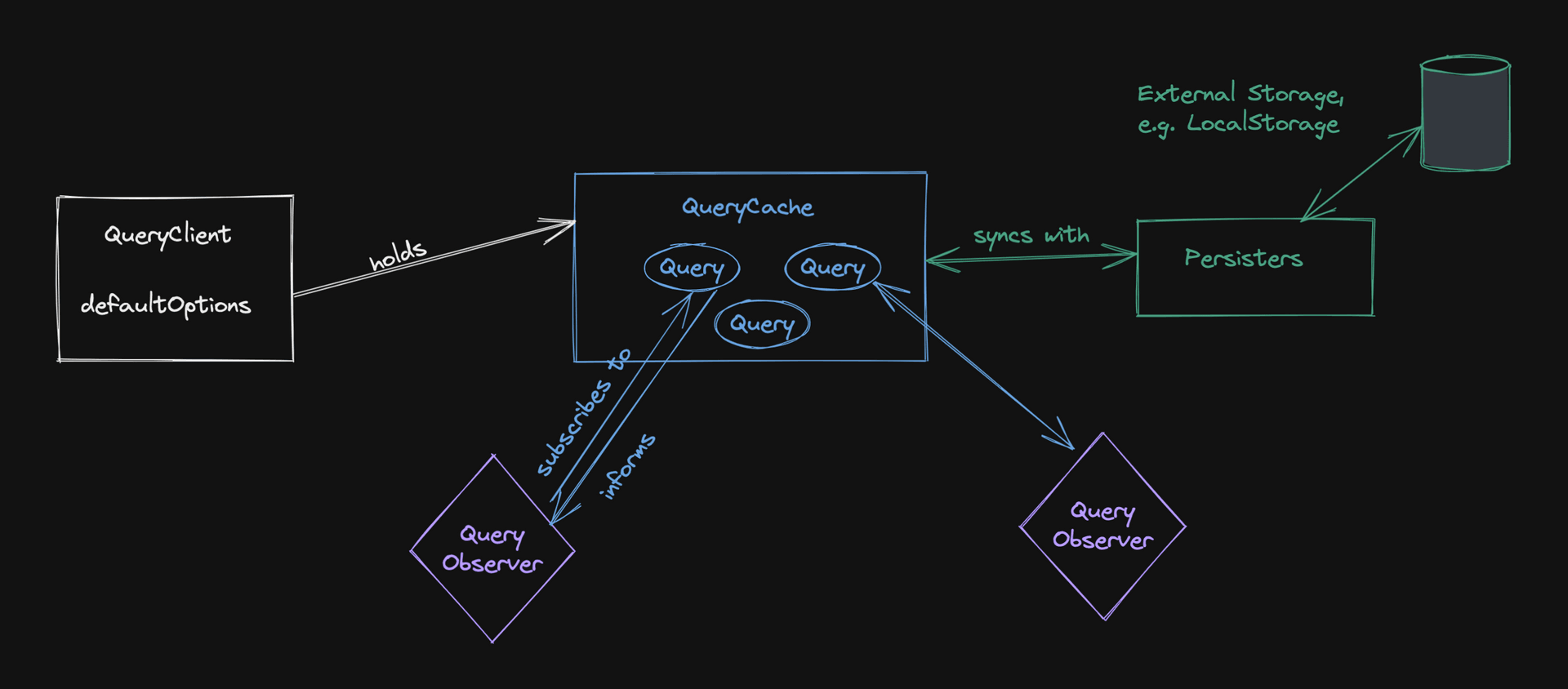
캐시에는 쿼리들이 있으며, Query에서 대부분의 로직이 실행된다. 여기에는 쿼리에 대한 모든 정보(데이터, 상태 필드 또는 마지막 fetching이 언제 발생했는지와 같은 메타 정보)가 포함될 뿐만 아니라 쿼리 함수를 실행하고 재시도, 취소 및 중복 제거 로직이 포함된다.
Query에는 우리가 불가능한 상태에 빠지지 않도록 하는 내부 상태 머신이 있다. 예를 들어 이미 fetching을 수행하는 동안 쿼리 함수를 실행해야 하는 경우 해당 fetch는 중복 제거될 수 있다. 쿼리가 취소되면 이전 상태로 돌아간다.
가장 중요한 것은, 쿼리가 누가 쿼리 데이터에 관심있는지를 알고 해당 관찰자에게 모든 변경 사항을 알릴 수 있다는 것이다.
QueryObserver
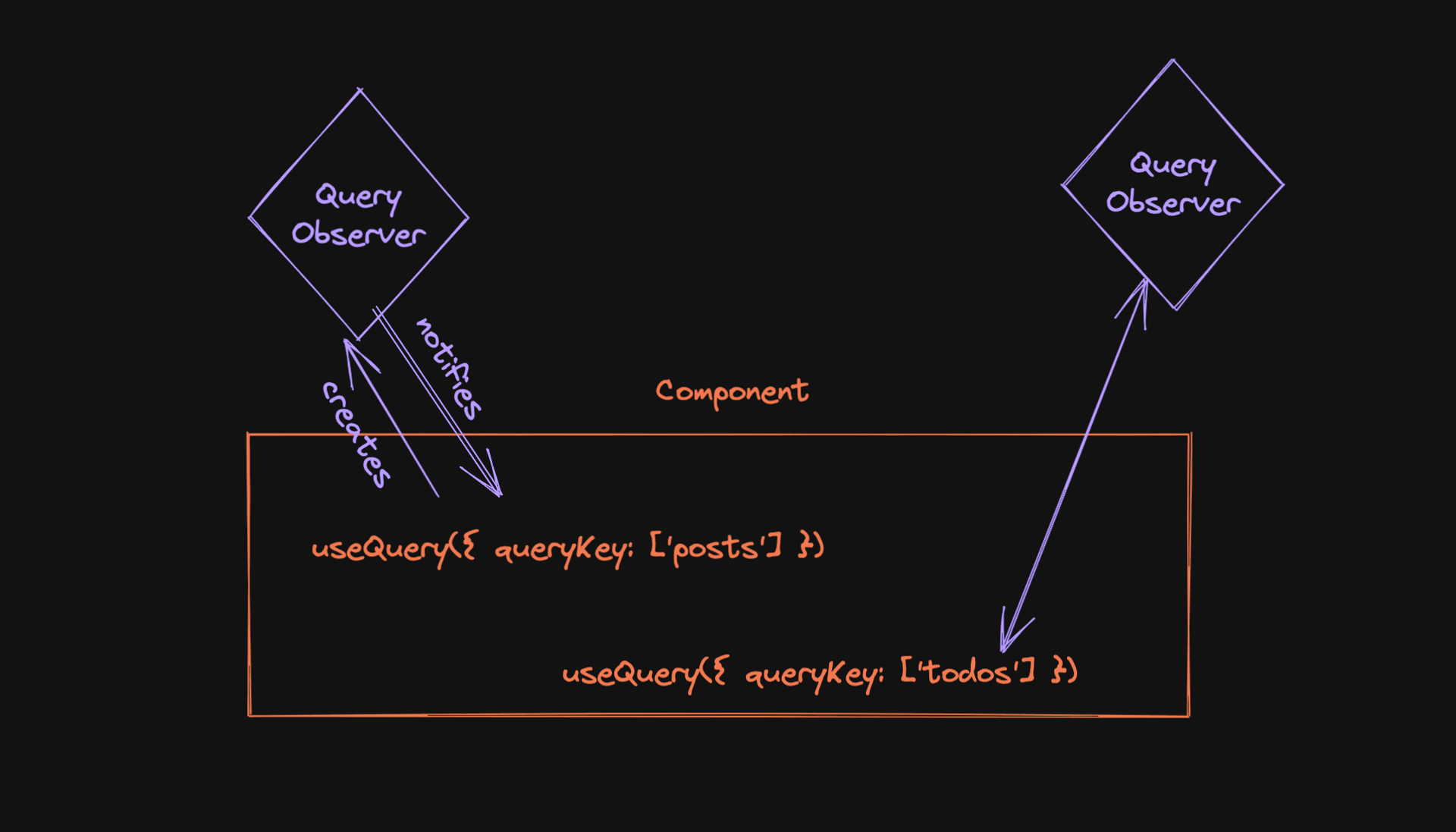 Observer는 쿼리와 이를 사용하려는 컴포넌트 사이의 접착제이다. Observer는
Observer는 쿼리와 이를 사용하려는 컴포넌트 사이의 접착제이다. Observer는 useQuery를 호출할 때 생성되며 항상 정확히 하나의 쿼리를 구독한다. 그렇기 때문에 useQuery에 queryKey를 전달해야 한다. 😉
Observer는 조금 더 많은 작업을 수행한다. Observer는 대부분의 최적화가 이루어지는 곳이다. Observer는 컴포넌트가 사용 중인 Query의 속성을 알고 있어, 관련 없는 변경 사항은 알릴 필요가 없다. 예를 들어 데이터 필드만 사용하는 경우 백그라운드 refetch에서 isFetching이 변경되는 경우 컴포넌트를 다시 렌더링할 필요가 없다.
추가로 각 Observer는 select 옵션을 가질 수 있으며 여기에서 데이터 필드의 어떤 부분에 관심이 있는지를 결정할 수 있다. 이전에 #2: React Query Data Transformations 에서 이 최적화에 대해 쓴 적이 있다. staleTime또는 interval fetching과 같은 대부분의 타이머는 observer-level에서도 발생한다.
Active and inactive Queries
Observer가 없는 Query를 비활성 쿼리라고 한다. 여전히 캐시에 있지만 어떤 컴포넌트에서도 사용되지 않는다. React Query Devtools를 살펴보면 비활성 쿼리가 회색으로 표시되는 것을 볼 수 있다. 왼쪽의 숫자는 쿼리를 구독하는 Observer의 수를 나타낸다.
The complete picture
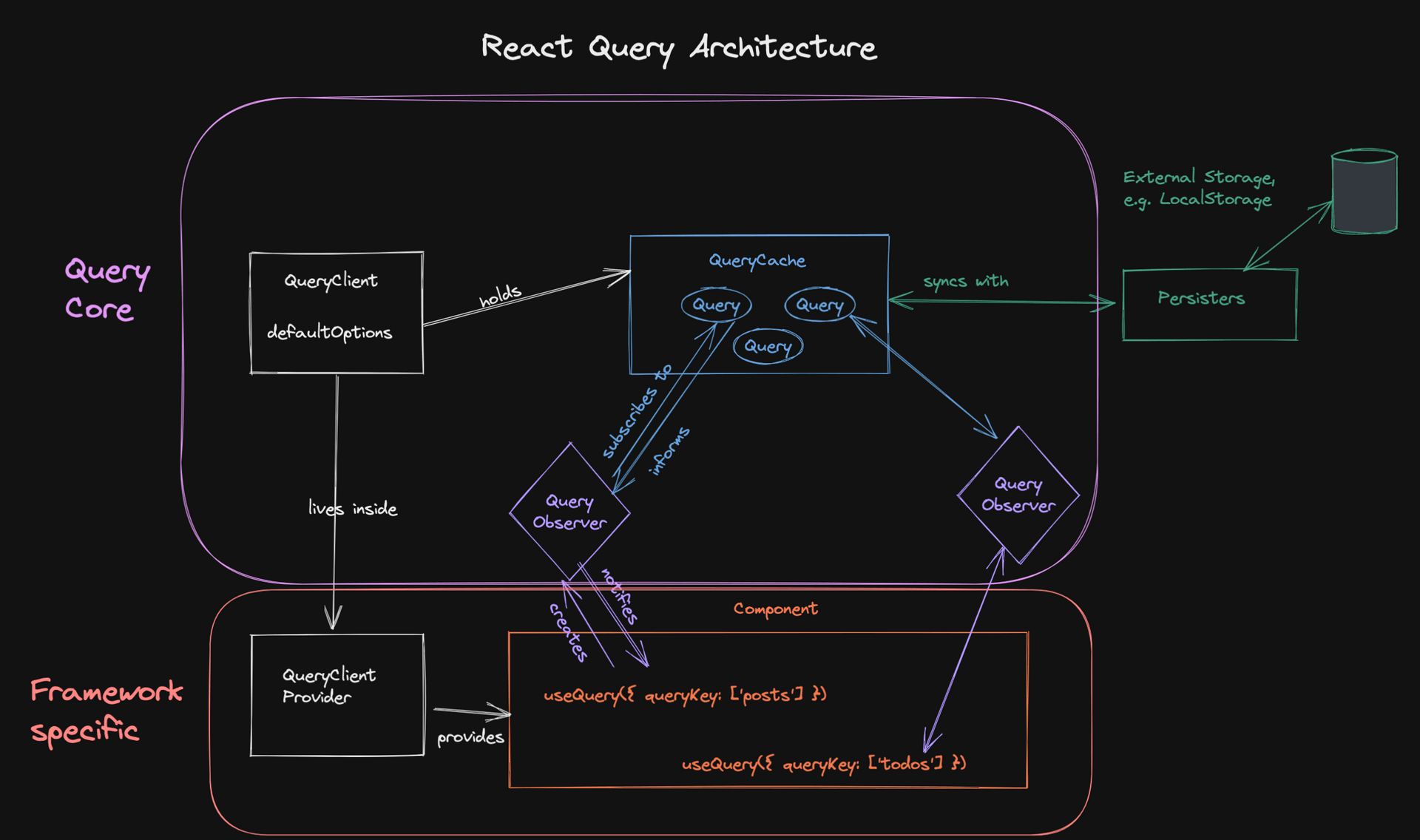 모두 합치면 대부분의 로직이 프레임워크에 구애받지 않는 Query Core(
모두 합치면 대부분의 로직이 프레임워크에 구애받지 않는 Query Core(QueryClient, QueryCache, Query, QueryObserver) 내부에 있음을 알 수 있다.
새 프레임워크용 어댑터를 만드는 것이 매우 간단한 이유이다. 기본적으로 Observer를 생성하고, 구독하고, Observer가 알림을 받으면 컴포넌트를 re-render하는 방법이 필요하다. react 및 solid 용 useQuery 어댑터에는 각각 약 100줄의 코드만 있다.
From a component perspective
마지막으로 다른 시각에서 흐름을 살펴보자 - 컴포넌트로부터 시작하는
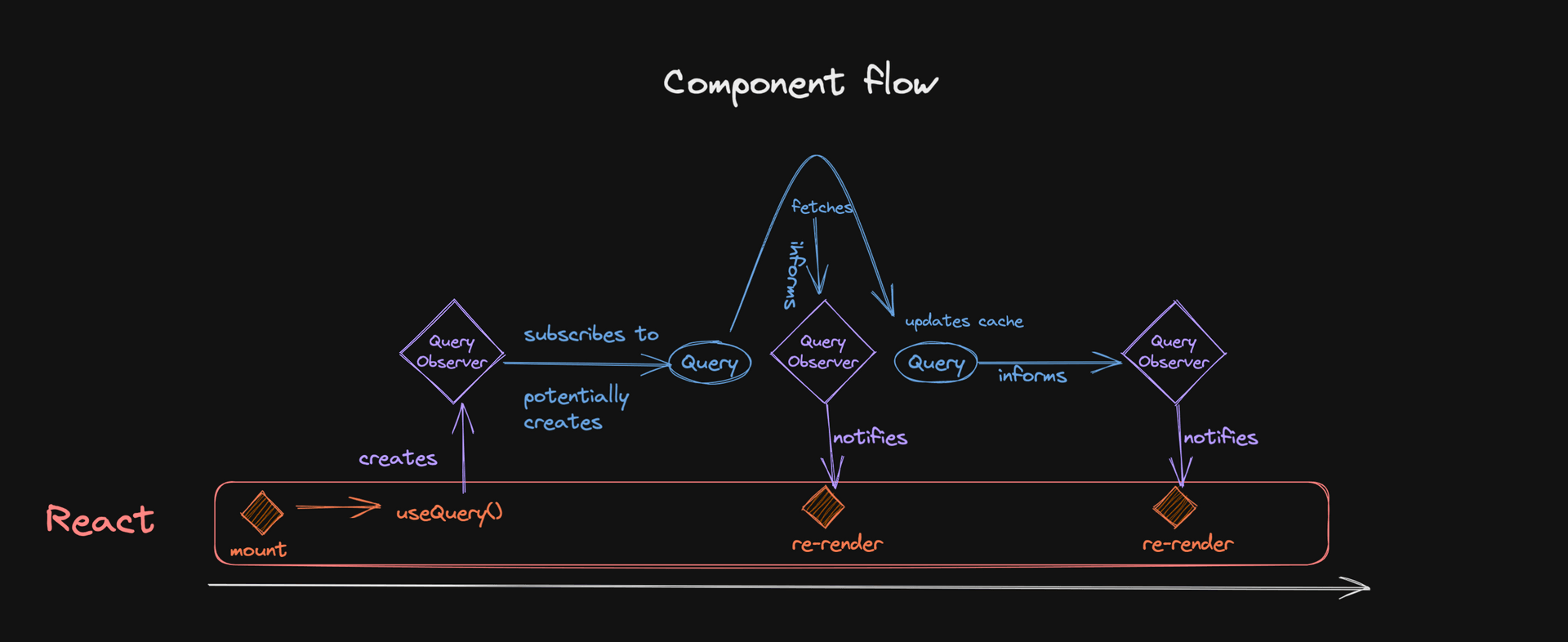
- 컴포넌트가 마운트되면
Observer를 생성하는useQuery를 호출한다. Observer는QueryCache에 있는Query를 구독한다.- 해당 구독은
Query생성을 트리거하거나(아직 존재하지 않는 경우) 데이터가 stale하다고 간주되는 경우 백그라운드 refetch을 트리거할 수 있다. - fetch를 시작하면
Query의 상태가 변경되므로,Observer에게 이에 대한 정보가 제공된다. Observer는 몇 가지 최적화를 실행하고 잠재적으로 컴포넌트에게 업데이트를 알리면, 새 상태를 render 할 수 있다.Query실행이 끝나면,Observer에게도 이 사실을 알린다.
이것은 많은 잠재적 흐름 중 하나일 뿐이라는 점에 유의해라. 이상적으로는 컴포넌트가 마운트될 때 데이터가 이미 캐시에 있을 것이다. 이에 대한 내용은 #17: Seeding the Query Cache 에서 읽을 수 있다.
모든 흐름에 대해 동일한 점은 대부분의 로직이 React(또는 Solid 또는 Vue) 외부에서 발생하고 상태 시스템의 모든 업데이트가 컴포넌트에 알려야 하는지 여부를 결정하는 Observer로 전파된다는 것이다.